A paper with the above provocative title started making the rounds back in 2022. While we originally discussed it over twitter, and some of our colleagues wrote longer responses on their blogs, we never wrote a long form response before. But since the paper keeps resurfacing from time to time, it seemed like a good idea to address it in depth, once and for all.
The paper in question can be read from here https://cs.brown.edu/people/acrotty/pubs/p13-crotty.pdf. The RavenDB guys, whose Voron DB engine was inspired by LMDB, wrote an excellent response here https://ravendb.net/articles/re-are-you-sure-you-want-to-use-mmap-in-your-database-management-system and we agree with it in its entirety, but of course we have a few other thoughts to add.
The paper's abstract gets off to a strident start:
There are, however, severe correctness and performance issues with mmap that are not immediately apparent. Such problems make it difficult, if not impossible, to use mmap correctly and efficiently in a modern DBMS.
The paper's authors have already painted themselves into a corner - claiming it's basically impossible to use mmap correctly means they've set out to prove a negative, which is a logical fallacy. The irony of this statement is that multipleresearchprojects have shown that LMDB is one of the only DB engines that consistently proves to have perfectly correct crash-resistance, while other DB engines using more traditional buffer pool management schemes have shown a variety of failure/corruption cases. As such, their paper's thesis is immediately invalidated.
In section 1 the paper's introduction again makes some ridiculous claims:
Unfortunately, mmap has a hidden dark side with many sordid problems that make it undesirable for file I/O in a DBMS. As we describe in this paper, these problems involve both data safety and system performance concerns. We contend that the engineering steps required to overcome them negate the purported simplicity of working with mmap. For these reasons, we believe that mmap adds too much complexity with no commensurate performance benefit and strongly urge DBMS developers to avoid using mmap as a replacement for a traditional buffer pool.
In order to make their case they would have to demonstrate that all DBMSs that use mmap are more complex than all DBMSs using a traditional buffer pool. They would also have to demonstrate that all DBMSs using mmap are less reliable and less performant than all DBMSs using a traditional buffer pool.
But they clearly can't demonstrate that, since LMDB safely addresses all concerns and is still the smallest most reliable database engine in the world, coming in at under 64KB of object code. Meanwhile, taking the traditional approach gives you DB engines that require orders of magnitude more code just to attempt to be correct, but still failing. Their assessment of complexity and correctness is completely wrong.
In section 2 their overview of mmap is basically correct. In 2.3 "MMAP Gone Wrong" they list a number of DBMSs that have successfully used mmap (including LMDB) and then they cite a number of well known examples of DBMSs that used mmap and got it wrong, including MongoDB and others. The whole section is difficult to take seriously; they claim it's nearly impossible to get it right and then give a list of projects that got it right. The ones who got it wrong are irrelevant, because simple and correct solutions clearly exist for all the potential problems.
In section 3 "Problems with mmap" we should be getting to the heart of the matter, but I find very little of interest here since LMDB has none of these problems. Their discussion of Shadow Paging that explicitly describes LMDB isn't even relevant, since by default LMDB doesn't use a writable mmap. As such their discussion of partial updates and msync doesn't even apply. These aspects of LMDB's behavior are well documented, so the fact they get this wrong reflects poorly on their research efforts.
In section 3.2 "I/O stalls" is again a non-issue; no matter how your DBMS handles I/O internally, synchronously or asynchronously, the calling application can't make any progress until the I/O completes, and if the data isn't already in memory then the application must wait.
In section 3.3 "Error handling" they correctly note "pointer errors might corrupt pages in memory" but that's why LMDB uses a read-only mmap by default. So again, non-issue. These problems are obvious to anyone contemplating such a design, and the solution is trivial, quite the opposite of the insurmountable, near-impossibility they claim.
In section 3.4 "Performance issues" - every benchmark shows that LMDB always massively outperforms every other DB engine on reads, so there's really nothing of substance here either. Page eviction is explicitly not an issue since LMDB uses a read-only mmap. That means all map pages are always clean; whenever memory pressure causes the OS to need to reclaim a page it can just do so immediately without having to evict/flush a page out. (Also the RavenDB blog post directly addressed the other points so I won't re-tread that ground.)
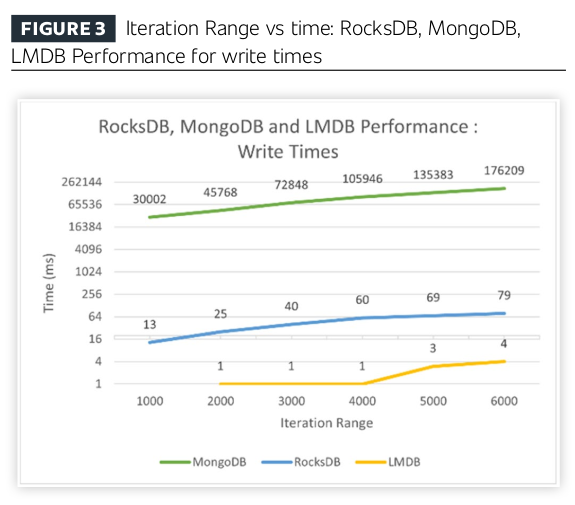
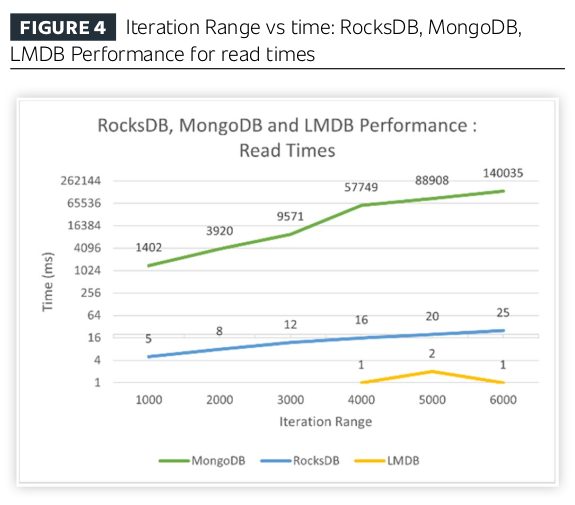
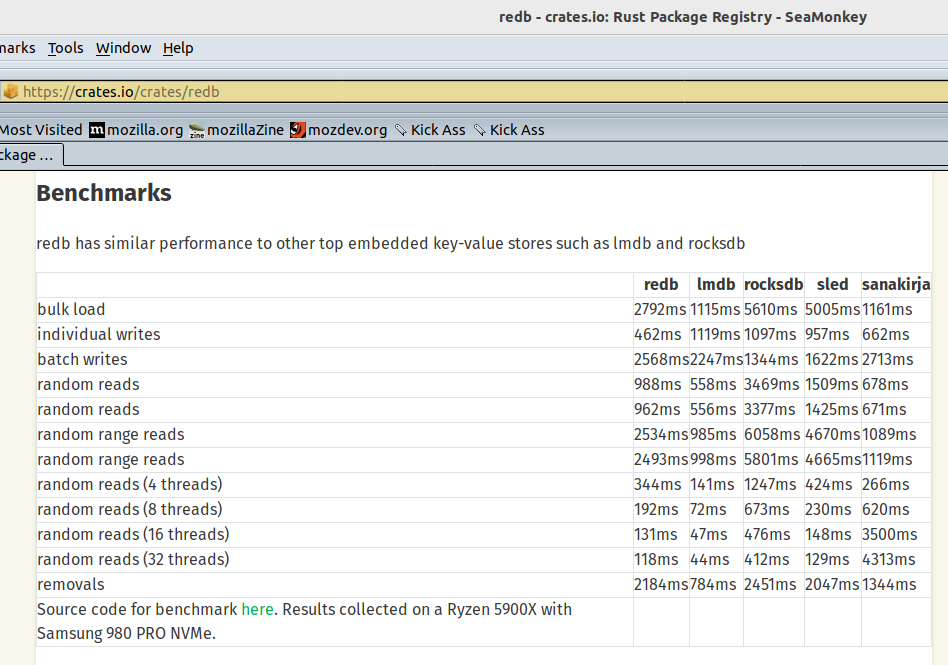
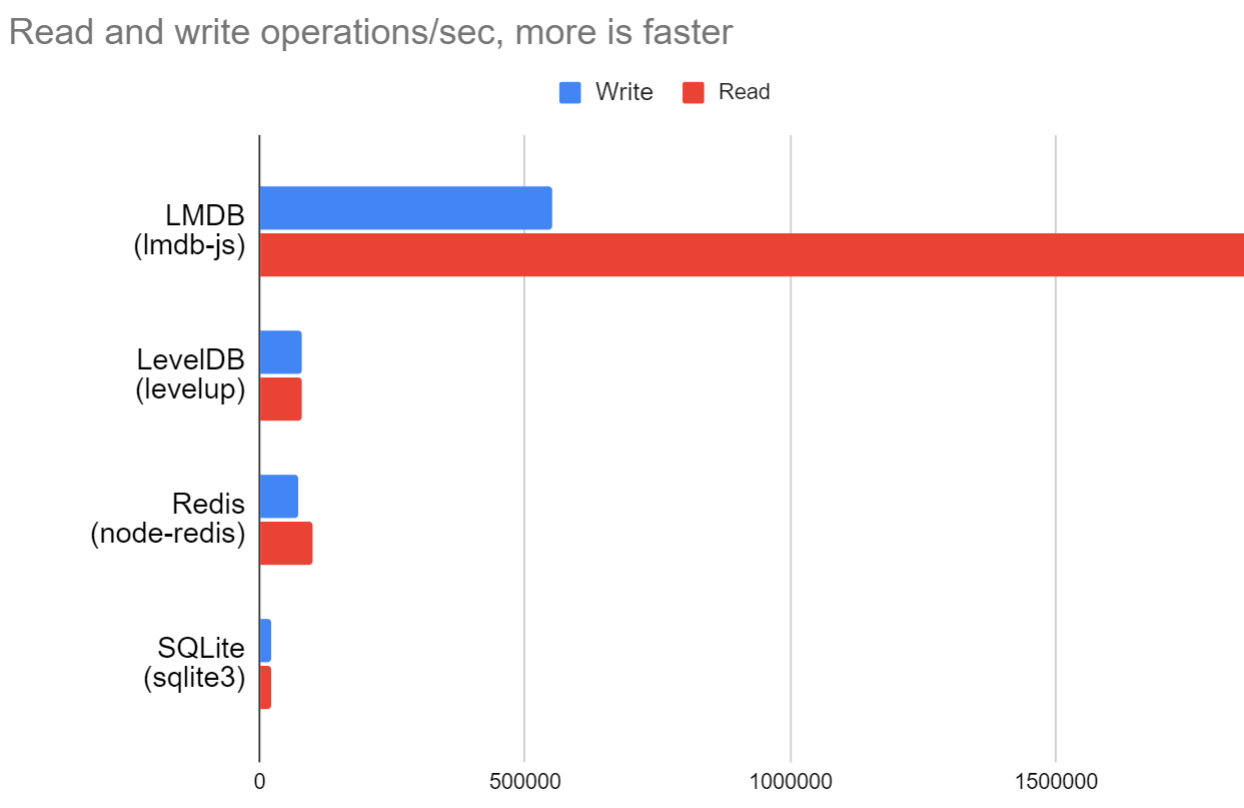
Section 4 "Experimental Analysis" really takes the cake - they test using fio, a filesystem benchmarking tool. They don't actually compare DBMS implementations, so none of their analysis takes into account the complexity and performance costs for a DBMS to not use mmap. They never demonstrate that any DBMS based on mmap is more complex than every DBMS that uses a traditional buffer pool, or that they are all less reliable or less performant. This is the heart of their paper and its comparisons are completely invalid, doing nothing to address their initial claims. This reason alone should have been enough to make the paper fail peer review; none of the work they did proves their thesis.
Section 6 Conclusion is just completely wrong:
"When you should not use mmap:"
"you need to perform updates in a transactionally safe fashion" - LMDB's ACID transactions are 100% perfectly safe.
"you need explicit control over what data is in memory" - on a machine with virtual memory, i.e., all modern operating systems, you never have this at application level.
"You care about error handling and need to return correct results" - LMDB always returns correct results.
"You require high throughput on fast persistent storage devices" - nothing beats LMDB on fast persistent storage devices http://www.lmdb.tech/bench/optanessd/
"When you should maybe use mmap in your DBMS"
"Your working set (or the entire database) fits in memory and the workload is read-only" - LMDB beats others for DBs much larger than memory, on read/write workloads http://www.lmdb.tech/bench/ondisk/
"You need to rush a product to the market and do not care about data consistency or long-term engineering headaches." LMDB is an open source project, we don't care about the market because we don't have to pay back any vulture capitalists. We took the time to do things right - which actually was a lot faster than doing things the traditional way.
"Otherwise, never." LOL.
Aside from the tremendous advantage in simplicity and robustness LMDB enjoys, there are other benefits not even touched on here, such as the fact that mmap solely uses the filesystem page cache means you can easily support multi-process concurrency, as well as multi-thread concurrency, without any additional memory overhead. No other DBMS engine can do that.
For as long as operating systems and database management systems have existed, there has been a rivalry between OS and DBMS developers. The DBMS guys always claim that because they have more intimate knowledge of the intricacies of the application workload, they can fine tune to deliver better performance. But all of that fine tuning comes at a tremendous cost in complexity, and the reality is, on a multiuser machine, they are dead wrong. Even on a dedicated single-user machine, it's far more complex and expensive for an application to collect all of the measurements and statistics needed to properly profile their workload, than it is to gather that information inside the kernel. But on a multiuser machine, where the DBMS shares the machine with other processes and other applications, it's impossible. No single process can obtain an accurate view of all system resource usage and demands; in fact it's the OS's job to hide such details from the application level. When you're sharing a machine with multiple other tasks, only the OS can ever truly know what's going on in the I/O susbsystem, in memory pressure, etc. etc.
The DBMS folks claim that knowing the intimate details of the workload can allow them to do more efficient caching. With a great deal of work that could be true on a dedicated machine, but on a shared machine, where all of your carefully managed buffers could get paged out at any time to satisfy other demands, the proposition is ludicrous. Also, there really aren't a lot of ways to beat a Least Recently Used (LRU) caching strategy. There are more efficient implementations (like CLOCK) but the overall strategy remains the same. And again LMDB leverages all of that with zero additional effort, because its B+tree design is naturally optimal with an LRU cache. Even when used with multiple tables, for separate indices and other metadata, because LMDB handles multiple tables as a tree of trees, it means the application doesn't need to care about which tables are used more frequently than others. They all start from the root of the LMDB B+tree, and an LRU mechanism will naturally sort their accesses out in order of recency.
Ultimately, the answer to the question "are you sure you want to use mmap in your DBMS?" should be rephrased - do you really want to reimplement everything the OS already does for you? Do you really believe you can do it correctly, better than the OS already does? The DBMS world is littered with projects whose authors believed, incorrectly, that they could.